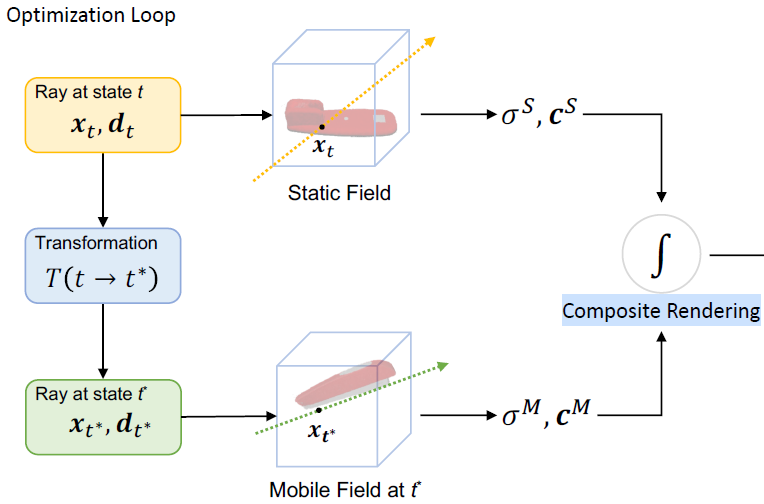
ABSTRACT: This paper introduces a self-supervised, end-to-end architecture that learns part-level implicit shape and appearance models and optimizes motion parameters jointly without requiring any 3D supervision, motion, or semantic annotation. The training process is similar to original NeRF but and extend the ray marching and volumetric rendering procedure to compose the two fields.
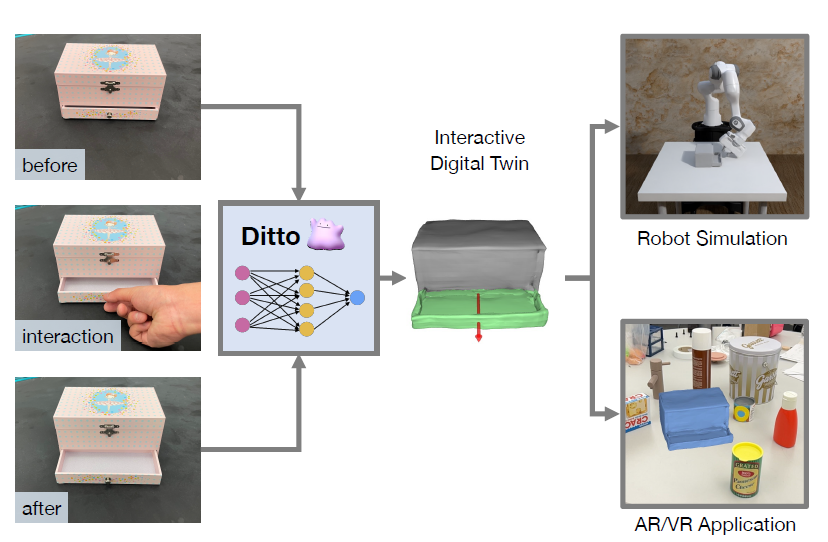
【Reading】Ditto-Building Digital Twins of Articulated Objects from Interaction
This paper propose a way to form articulation model of articulated objects by encoding the features and find the correspondence of static and mobile part via visual observation before and after the interaction.
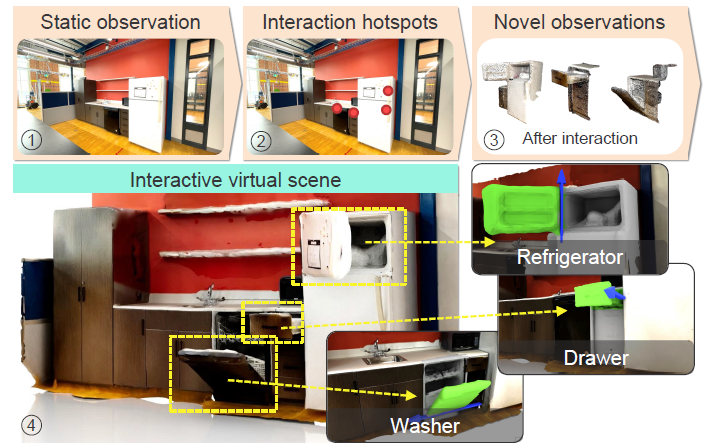
【Reading】Ditto in the House-Building Articulation Models of Indoor Scenes through Interactive Perception
The paper proposed a way of modeling interactive objects in a large-scale 3D space by making affordance predictions and inferring the articulation properties from the visual observations before and after the self-driven interaction.
【Reading】LATITUDE:Robotic Global Localization with Truncated Dynamic Low-pass Filter in City-scale NeRF
This paper proposes a two-stage localization mechanism in city-scale NeRF.

Reading:"NeRF:Representing Scenes as Neural Radiance Fields for View Synthesis"
This is a summary for paper “NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis”.
Keywords: scene representation, view synthesis, image-based rendering, volume rendering, 3D deep learning