This paper propose a way to form articulation model of articulated objects by encoding the features and find the correspondence of static and mobile part via visual observation before and after the interaction.
Workflow-In Brief
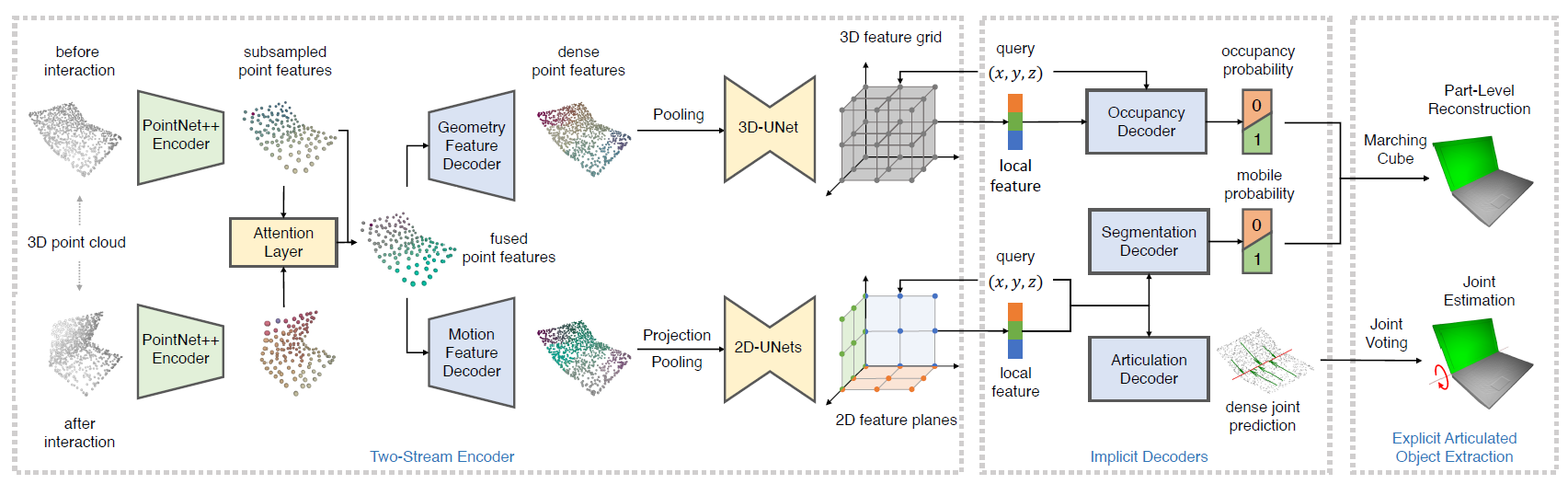
Two Stream Encoder
Given point cloud observations before and after interaction: P1,P2∈RN×3
Encode them with PointNet++ Encoder μenc: f1=μenc(P1), f2=μenc(P2). f1,f2∈RN′×dsub. N′<N is the number of the sub-sampled points, and dsub is the dimension of the sub-sampled point features.
Fuse the features with attention layer: Attn12=softmax(dsubf1f2T)f2, f12=[f1,Attn12], f12∈RN′×2dsub.
The fused feature is decoded by two PointNet++ decoder νgeo, νart, and get fgeo=νgeo(f12), fart=νart(f12). f1,f2∈RN×ddense are point features aligned with P1
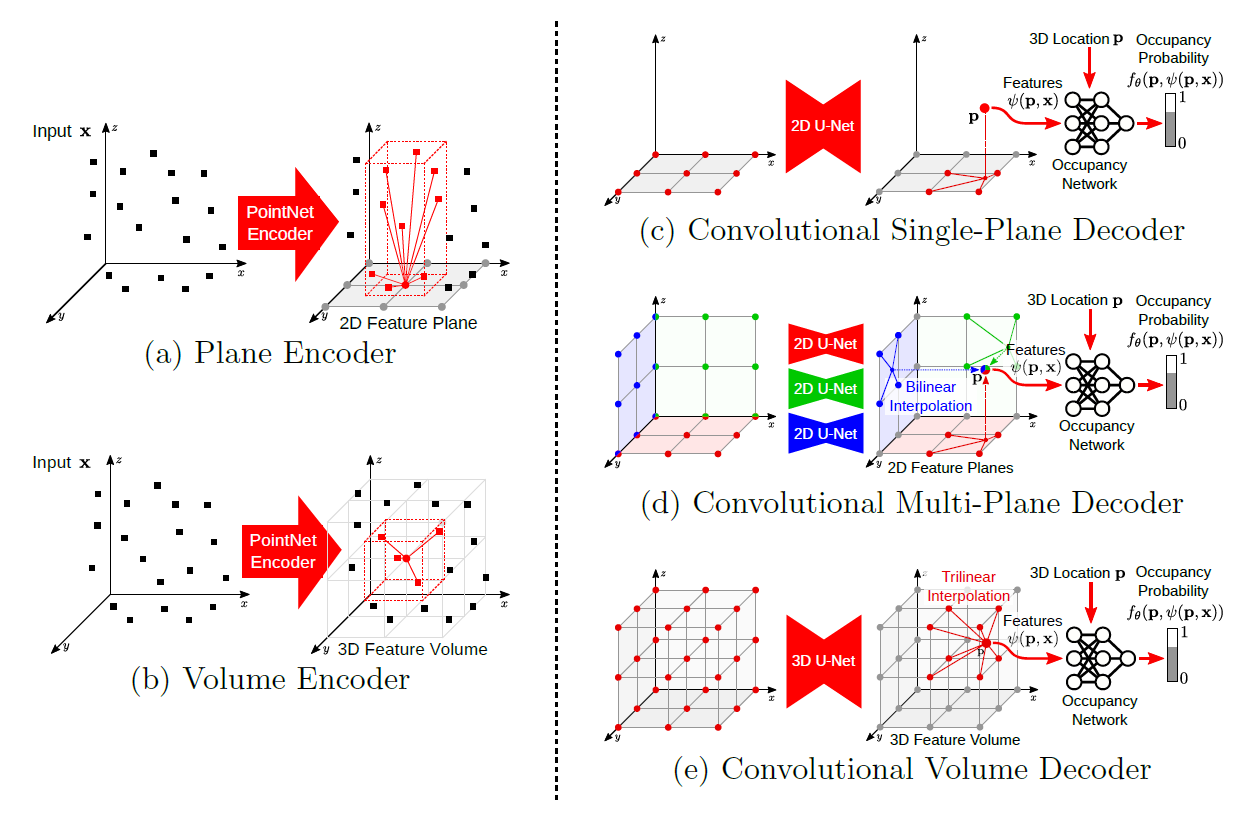
Feature encoding based on ConvONet.
fart is projected into 2D feature planes and fgeo is projected into voxel grids as in the ConvONets. The points that fall into the same pixel cell or voxel cell are aggregated together via max pooling.