The paper proposed a way of modeling interactive objects in a large-scale 3D space by making affordance predictions and inferring the articulation properties from the visual observations before and after the self-driven interaction.
Workflow-In brief
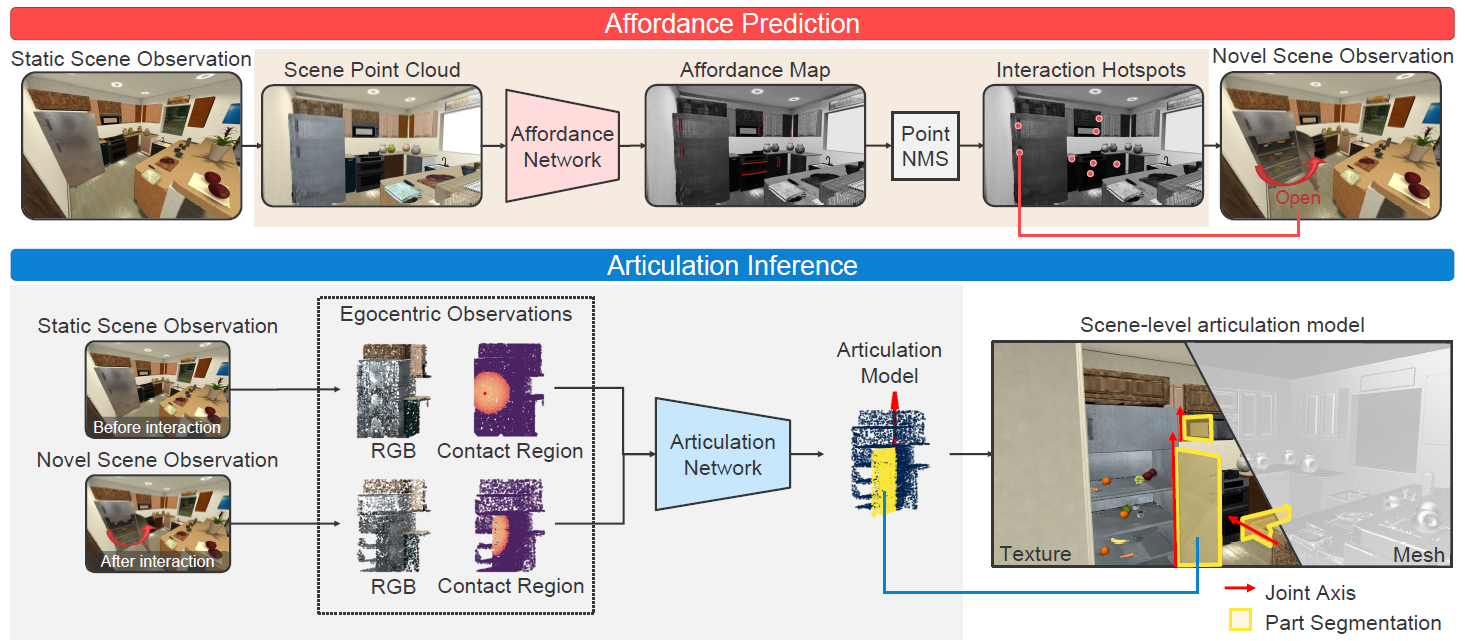
Given Initial scene observation , each point is a 6D vector .
Get an affordance map and samples peak locations as interaction hotspots (The locations where the robot can successfully manipulate the articulated objects, and infer the articulation model) from observation .
For each interaction, robot applies force to the hotspot to produce potential articulated motions.
Sample point cloud , center on the interaction hotspot before and after the interaction.
Record contact location .
An articulation inference network segments the point cloud into static and mobile parts based on .
Estimate articulation parameters. [1]
Prismatic joint: , where is the translation axis, is the joint state, which is the relative translation distance.
Revolute joint: , where is the revolute axis, is the pivot point on the revolute axis, is the joint state, which is the relative rotation angle.
Map the estimated articulation model of each object from the global frame. The set of these articulation models constitutes the scene-level articulation model .
Modules-In detail
Affordance Prediction
Estimation based on PointNet++[2]
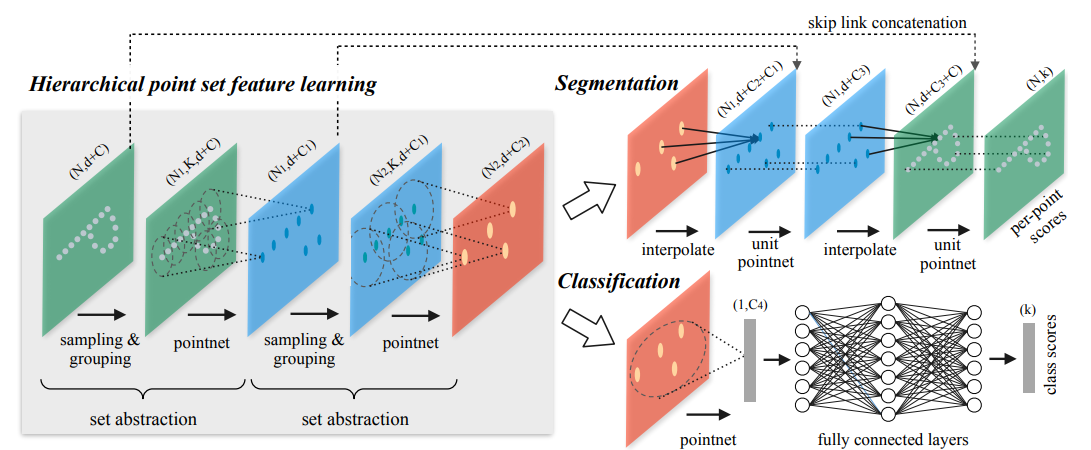
The prediction problem is modeled as a binary classification problem. The observation point cloud is fed into PointNet++ to get a point-wise affordance map.
- Exploration driven training: We first uniformly sample locations over the surface of both articulated and non-articulated parts, then have the robot interact with them. If the robot successfully moves any articulated part of the
objects, we label the corresponding location as positive affordances or negative otherwise. - To simulate gripper-based interactions, we perform a collision check at each location to ensure enough space for placing a gripper.
- The virtual robot interacts with the object as in reality (Pull, push or rotate).
- For each successful interaction, we collect the robot’s egocentric observations before and after interaction and the object’s articulation model as training supervision.
- The data distribution is imbalanced due to the large proportion of negative data. To mitigate the imbalance problem, we optimize the network with the combination of the cross-entropy loss and the dice loss。
- Exploration driven training: We first uniformly sample locations over the surface of both articulated and non-articulated parts, then have the robot interact with them. If the robot successfully moves any articulated part of the
Non-maximum suppression (NMS) for peak selection
- select the point with the maximum score and add it to the preserving set.
- Suppress its neighbors by a certain distance threshold.
- Repeat this process until all points are added to the preserving set or suppressed.
Articulation Inference
Ditto: Building Digital Twins of Articulated Objects [3]
The occupancy decoder is discarded.
Refinement
The estimated articulation model could have a higher accuracy if the observations covered significant articulation motions and a complete view of the object’s interior. However, these
observations may be partially occluded due to ineffective actions.
eg. we find that articulation estimation of a fully opened revolute joint, like , is more accurate in terms of angle error than one with an ajar joint.
Accordingly, we develop an iterative procedure of interacting with partially opened joints and refining the articulated predictions.
we exploit the potential motion information from the previous articulation model and extract the object-level affordance.
We refine the affordance prediction by selecting a pair of locations and actions to produce the most significant articulation motion. We set the force direction as the moment of the axis.
Given the joint axis and part segment, we select the point in the predicted mobile part farthest from the joint axis as our next interaction hotspot.
References
[1] Li, X., Wang, H., Yi, L., Guibas, L. J., Abbott, A. L., & Song, S. (2020). Category-level articulated object pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 3706-3715). https://arxiv.org/abs/1912.11913
[2] Qi, C. R., Yi, L., Su, H., & Guibas, L. J. (2017). Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Advances in neural information processing systems, 30. https://arxiv.org/abs/1706.02413
pointnet arxiv.org/pdf/1612.00593.pdf