In this note we connect the energy concepts including Lagrangian Dynamics and Gibbs Formula to measuring the quality of prediction. Then we go over the inferencing and training in multi-modal scenarios.
This is one part of the series about energy-based learning and optimal control. A recommended reading order is:
- Notes on “The Energy-Based Learning Model” by Yann LeCun, 2021
- Learning Data Distribution Via Gradient Estimation
- From MPC to Energy-Based Policy
- How Would Diffusion Model Help Robot Imitation
- Causality hidden in EBM
Recording Link: Yann LeCun | May 18, 2021 | The Energy-Based Learning Model
Further Readings: A Tutorial on Energy-Based Learning
Reformulation of Back-propagation as Lagrangian Optimization
Instead of forces, Lagrangian mechanics uses energy as a unified parameter. A Lagrangian is a function which summarizes the dynamics of the entire system. The non-relativistic Lagrangian for a system of particles in the absence of an electromagnetic field is given by
where denotes total kinetic energy of the system and denotes the total potential energy, reflecting the energy of interaction between the particles. The optimization target is to minimize
Lagrange’s Equations for a time varying system with number of constraints being . Particles are labeled as and have positions and velocity .
For each constraint equation , there’s a Lagrange multiplier
Gibbs Formula [TODO]
Gibbs energy was developed in the 1870’s by Josiah Willard Gibbs. He originally termed this energy as the “available energy” in a system. His paper “Graphical Methods in the Thermodynamics of Fluids” published in 1873 outlined how his equation could predict the behavior of systems when they are combined. This quantity is the energy associated with a chemical reaction that can be used to do work, and is the sum of its enthalpy and the product of the temperature and the entropy of the system.
Further reading: The Markov blankets of life: autonomy, active inference and the free energy principle
Statement in DL
Loss
- s.t. ,
Lagrangian for optimization under constraints
Optimality conditions
In back propagation, the Lagrange multiplier is the gradient
Self Supervised Learning

- Learning hierarchical representations
- Learning predictive models
- Uncertainty/multi-modality?
Energy Based Model
Using divergence measure as metrics cannot deal with futures with multiple possibilities (e.g. Multiple solutions in path planning). The average of all possibilities will possibly be the optimal result in such metrics, overfitting may also occur for datasets of insufficient samples.
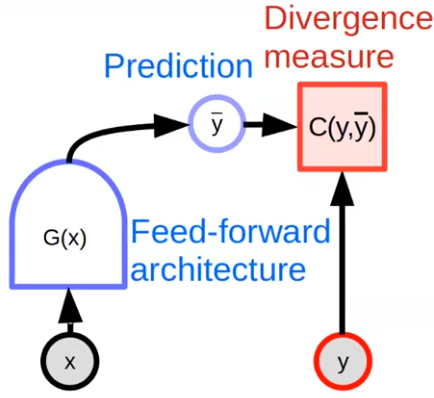
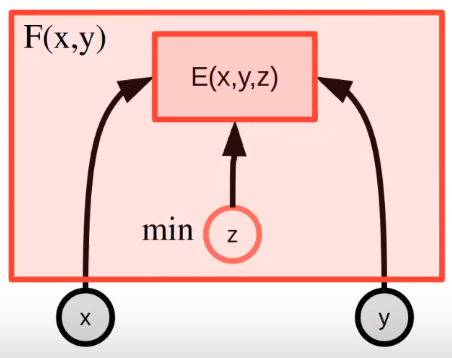
We can replace the divergence measure with an energy function, which measures the “incompatibility” between and . the compatible solution can be inferred using gradient descent, heruistic search etc.
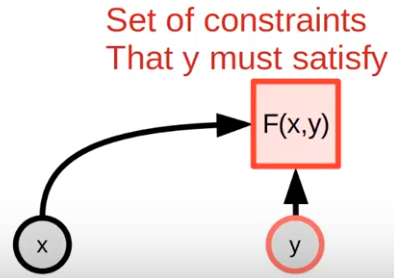
Now the target becomes “Finding an output satisfying the constraints”.
An unconditional EBM measures the compatibility between components of .
For a conditional EBM , we have low energy near provided data points, while higher energy for everywhere else.
(PS. This optimization is in inference process)
As a visualization:
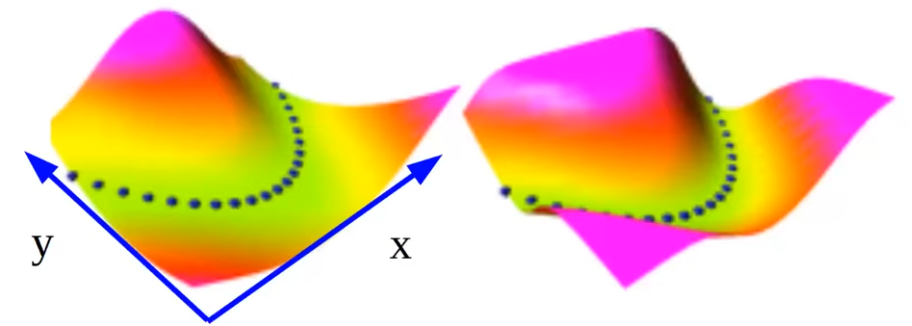
Probabilistic models are a special case of EBM. Energies are like un-normalized negative log probabilities 1 . If we want to turn energy functions as distributions, we can use Gibbs-Boltzmann distribution, which adopts maximum entropy approach and Gibbs formula.
is a positive constant. However the normalization constant at denominator is often intractable. One possible solution is to learn the log-likelihood of , and the distribution is changed intoEBM for Multi-Modal Scenarios
Joint Embedding
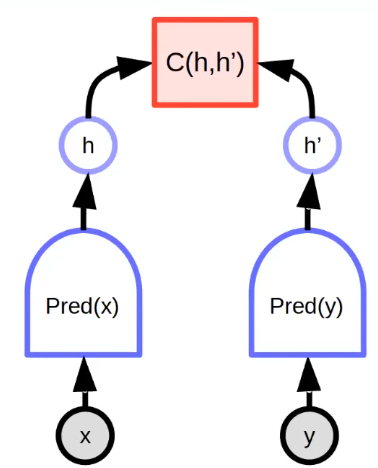
For the above example, the energy function is trained with the similarity of and . There may exist multiple unseen that has the same , and we may quantify those unseen by projecting them into the invariant subspace of latent .
Latent Generative EBM
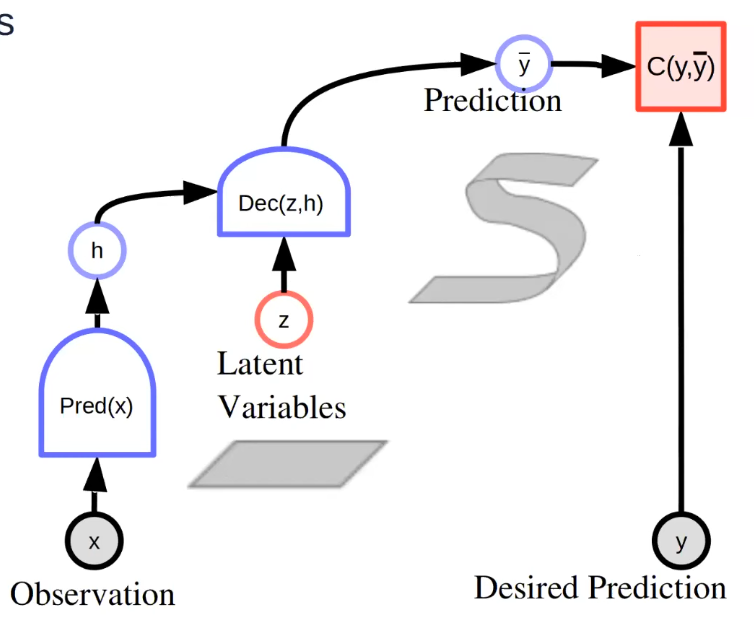
- Ideally the latent variable represents the independent explanatory factors of variation of prediction. But since it’s unobservable, information capacity of latent variable must be minimized.
- We may also see it as a “bias”, or a placeholder for uncertainties.
The inference can be formulated as:
However the latent variable is not presented and cannot be measured in supervised manner. So we will have to minimize its effect.
 is a free energy model and constrained on "temperature" term as previously shown in Gibbs-Boltzmann distribution. In practice, can be a variance schedule (eg. DDPM).
is a free energy model and constrained on "temperature" term as previously shown in Gibbs-Boltzmann distribution. In practice, can be a variance schedule (eg. DDPM).
If we try to understand this in a causal approach, we can treat as a unobserved confounder, which causes a biased estimation of the effect of on .
This operator means an intervention (or call it adjustment) of . The intervention cannot “back-propagate” to confounder thus the result is changed.
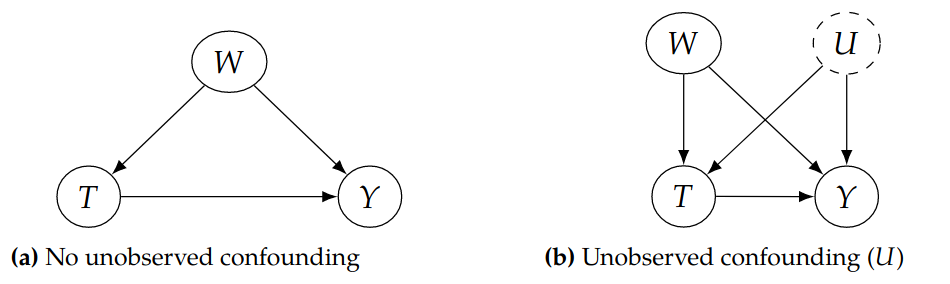
The “adjust formula” provides an unbiased solution by taking all into consideration. However the domain of is often intractable and we need to regularize it so it’s small enough to neglect.
On the contrary, we can also examine the robustness of with sensitivity analysis. This connects to the concept of “quantify the uncertainty of unseen by projecting them into the invariant subspace of latent “ mentioned above.
For those may be interested: Sensitivity analysis of such EBM:
*For simplicity, we directly write for . *
If we treat the above generative EBM as a causal graph, assuming linear relationship among variables (non-linear scenes will be derived in the following posts), we will have:
We can obtain the confounding bias by adjusting , leading to different , and gets confounding bias:
The Average total Effect (ATE) of on is as
By assuming the distribution of , we can derive the uncertainty of by “propagating”.
We can use the Fisher Information, which is defined to be the variance of the score function, to further state the uncertainty. This will come in the next post that provides a more detailed formulation of score function and EBM.
Training of EBM
Shape so that:
- is strictly smaller than for all different from .
- Keep smooth. (Max-likelihood probabilistic methods breaks this) More
Existing approaches:
Contrastive-based
where is negative sample.
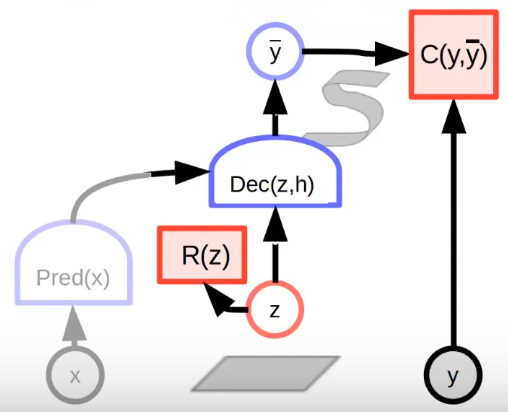
Regularized / Architectural methods: Minimize the volume of low-energy regions.
e.g. Limit the capacity of latent:
Appendix
Why Max-Likelihood Sucks in Contrastive Method

Makes the energy landscape into a valley.
- 1.Further readings of learning data distributions: Generative Modeling by Estimating Gradients of the Data Distribution↩
- 2.KL divergences are comparisons between Gaussians, so they can be calculated in a Rao-Blackwellized fashion with closed form expressions instead of high variance Monte Carlo estimate↩