ABSTRACT: This paper introduces a self-supervised, end-to-end architecture that learns part-level implicit shape and appearance models and optimizes motion parameters jointly without requiring any 3D supervision, motion, or semantic annotation. The training process is similar to original NeRF but and extend the ray marching and volumetric rendering procedure to compose the two fields.
[Arxiv] [Github] [Project Page]
Problem Statement
The problem of articulate object reconstruction in this paper can be summarized as: Given start state and end state and corresponding multi-view RGB images and camera parameters.
The first problem is to decouple the object into static and movable part. Here the paper assumes that an object has only one static and one movable part.
The second problem is to estimate the articulated motion . A revolute joint is parametrize as a pivot point and a rotation as quaternion , . A prismatic joint is modeled as a joint axis as unit vector and a translation distance . The training process will adapt one of them as prior info states. If no such prior info is given, the motion is modeled by .
Method
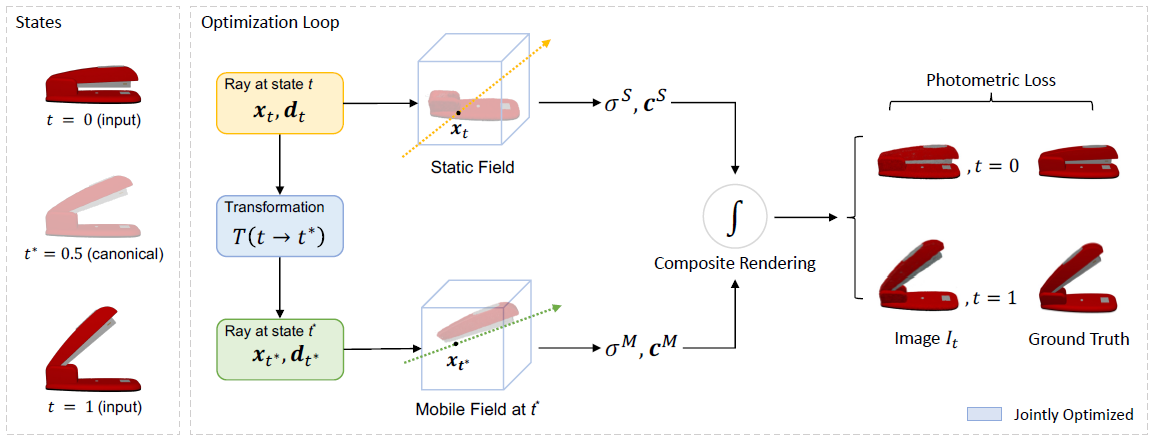
This paper divides the parts by registration on input state to a canonical state . The components agrees with the transformation is extracted as moving part and the remaining as the static part.
Structure
Static and moving part are jointly learnt during training and they are built separately on networks with the same structure that built upon InstantNGP. Their relationship is modeled explicitly as the transformation function as described in Problem Statement.
The fields are represented as:
Here is a point sampled along a ray at state with direction. . is the density value of the point x, and is the RGB color predicted from the point x from a view direction .
Training
The adapted training pipeline is similar to NeRF and the ray marching and volumetric rendering procedure to compose the two fields is extended.