Abstract To avoid shared memory conflict in shared memory for each thread in different banks, swizzling is invented to create offsets for memory allocation. Which means, finding places for the memory that requested by a Layout.
In computer graphics, swizzles are a class of operations that transform vectors by rearranging components. Swizzles can also project from a vector of one dimensionality to a vector of another dimensionality, such as taking a three-dimensional vector and creating a two-dimensional or five-dimensional vector using components from the original vector.
Wikipedia, "Swizzling"
Previously: Hierarchical Tensor and the Story of Indexing
Reference Link: cutlass
Motivation
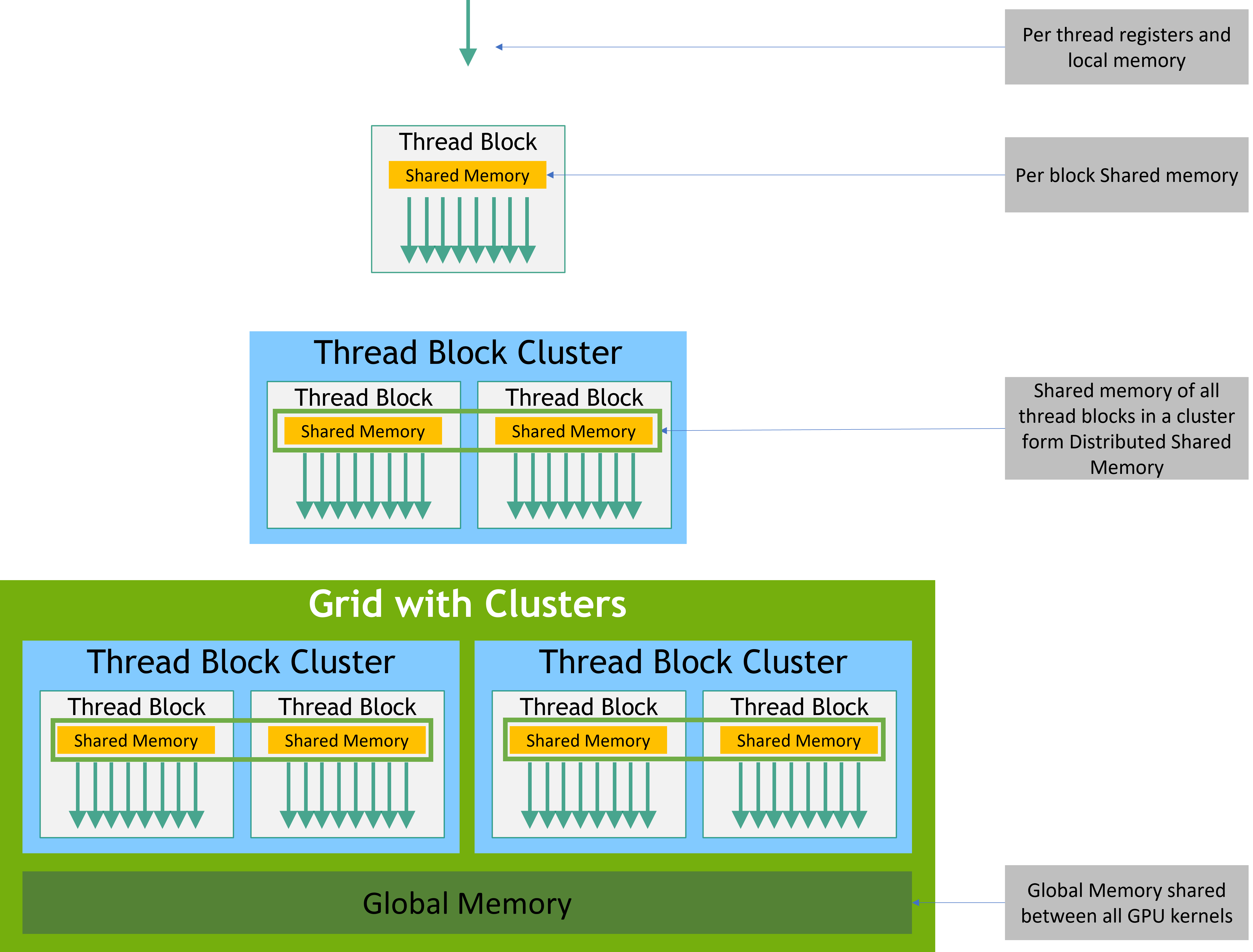
Each thread are having their own memory. However, in tasks that needs
the joint forces of threads, a shared memory is needed to perform better
cooperation. For example, for the tasks of GEMM like
Everything looks well, isn't it?
What if they don't?
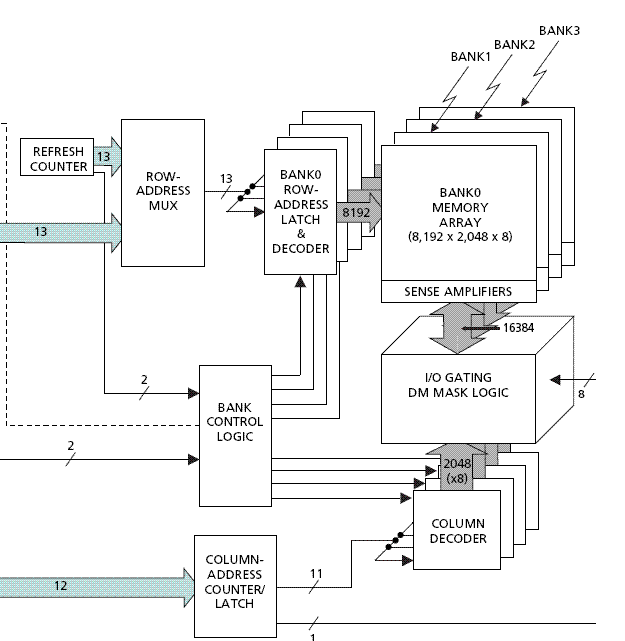
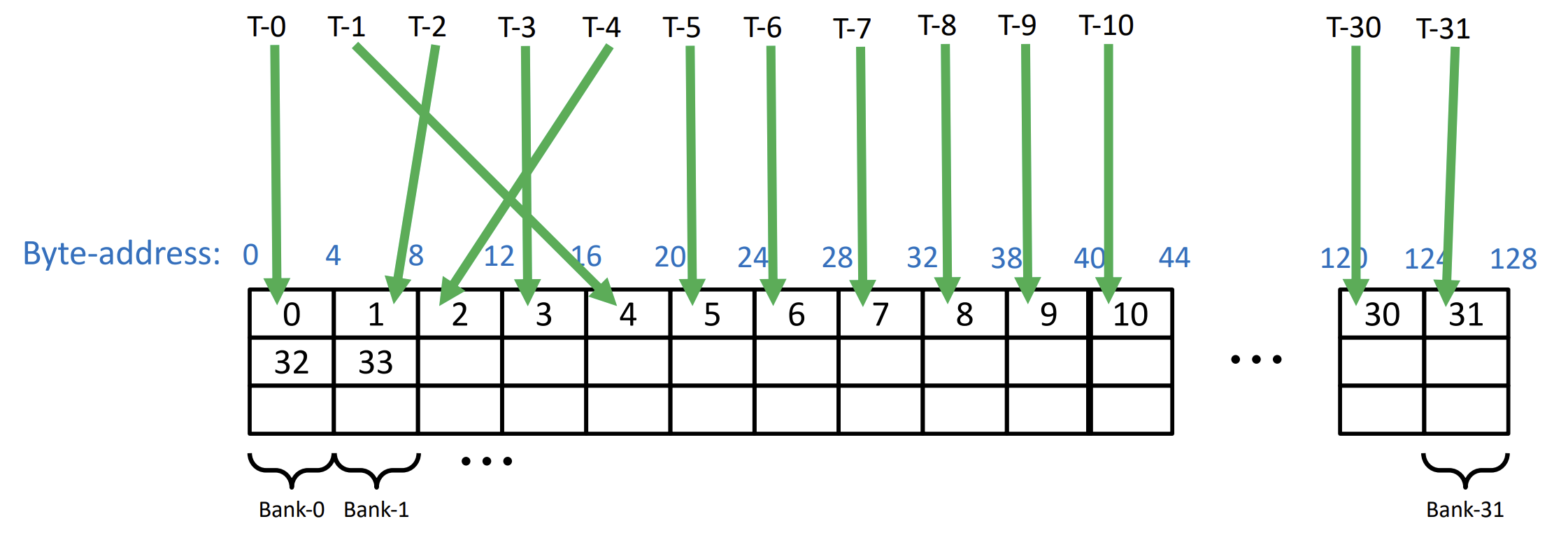
Let's first have a glance at how threads extract bits from RAM. To access data, threads provide memory addresses they want, memory controllers will map them into chip selection signal, bank selection signal and physical address on chip(Row and column). Building the mapping of addr->(bank, physical address). Moreover, the each bank and address index can only be used once. Thus, when it comes to situation where threads are trying to access different address of the same bank, it will cause a "BANK CONFLICT" which makes the data retrieval cannot be done in a single clock cycle.
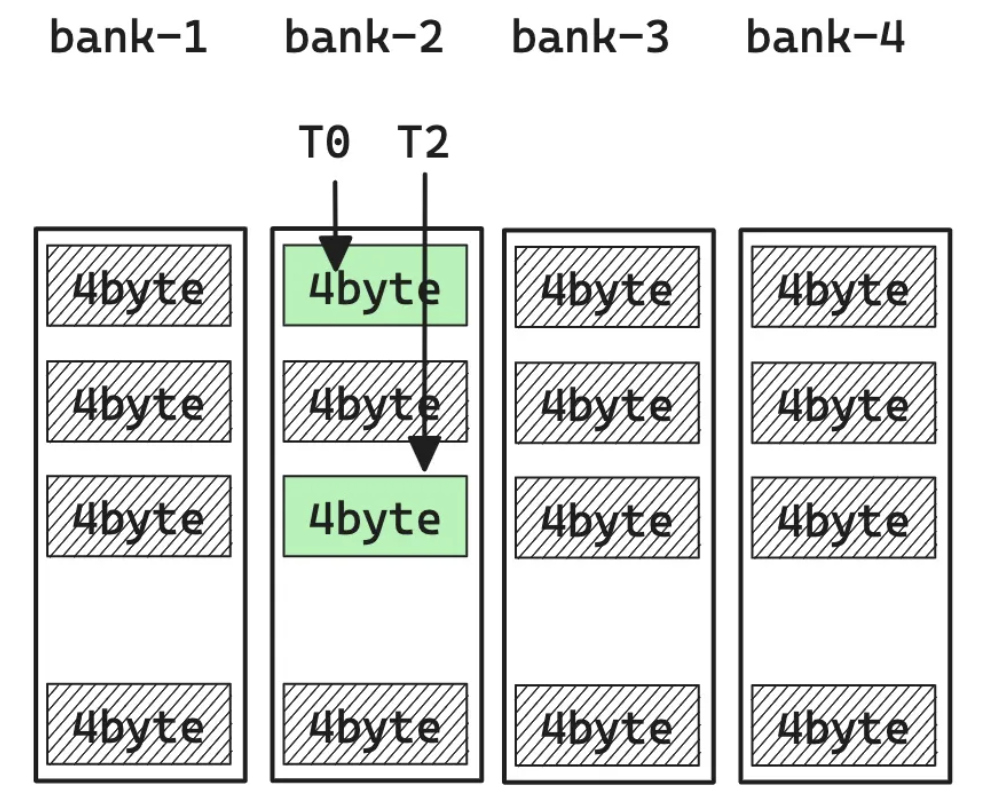
To accelerate the process, people have develop a way of mapping that can maximize the data extracted in each clock cycle. This is the "swizzling" we are talking about today.
To simplify the entire process, we will state the physical address as row and banks as column. So the entire memory model looks like a big rectangle.
Method
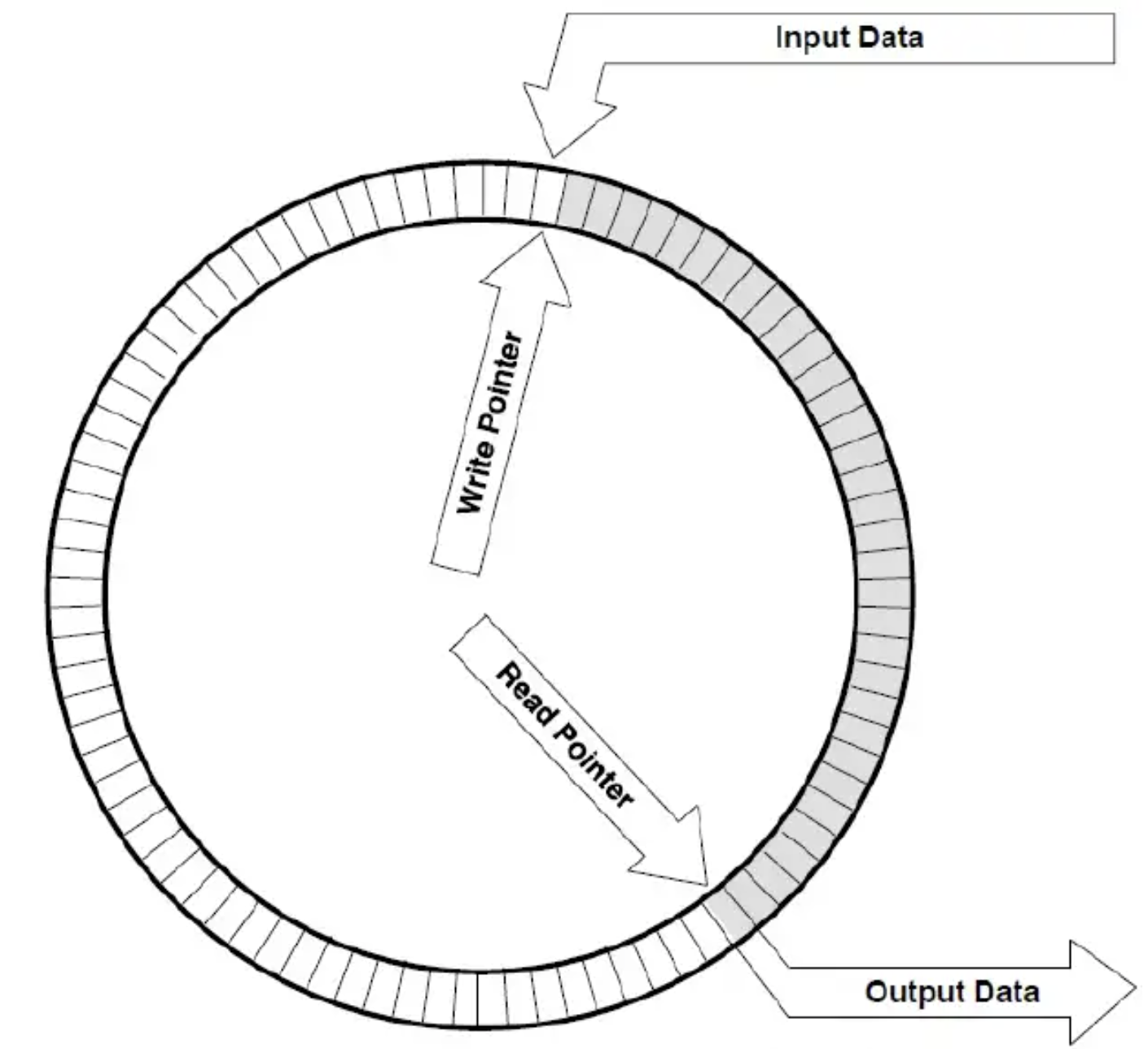
Let me try to revoke your memory about Data structure lectures. You may have heard about "Circular Queue", and the core of it is taking the remainder as index of head and tail. This is also the core spirit of swizzling.
1 | class CircularQueue(): |
The swizzling problem can be modeled as follows. Given the memory
offset from Layout, which can be seen as the logical
address, the Swizzle method is required to find out the
physical address on the chip.
So we can build a class like this, which can be called by
Swizzle(Layout(index)):
1 | class Swizzle: |
In one word, there will be
The maximum "width" of threads shall be
Let's first consider the situation where we can query all data we need in one cycle, which means every bank only contains just 1 or 0 "base" block.
Since no banks will show up for the second time, we can simplify it
as the circular queue above. Inside the big "queue", all banks are
allocated equal size of "sub-queues", whose head address (Remember the
unit is index of Layout) can be:
1 | rear = (rear + 2^B) % size |
The size is Layout index.
Wait...How can we get the rear here?
Clearly the rear is similar to offset, and it's related
to the pointers that steps towards after each insertion. We only need to
convert it to the index in the unit of Layout index.
1 | blk = offset//(2**M) # number of blocks ahead of index we look for |
Looks easy, isn't it? However, these operations are a bit slow in calculation, so we can setup them as shifting and bitwise operations.
Actually, we can simply send the offsets to where they need to go and do calculations with the corresponding slices, and ignore other digits!
How can we send them there? Where is the corresponding slices?
First, let's rethink the sub-queue example. An offset can be hashed
into a (bnk, thd, blk). Among
these variables, who can appear for the second time for another offset
without causing bank conflict?
The answer is bank!
(Hint, think of the stages where banks are not enough and we need to visit RAM for the second time)
Let's take a 32bit logical address as example:
1 | assign offset[31:0] |
p.s. You can read more about XOR and its applications by learning about Cyclic Redundancy Check.
Conclusion
what a marvelous journey back to discrete mathematics, computer architecture and Verilog! This implementation has provided me with a tremendous insight into the application of number theory in designing memory mapping. Previously what I am trying to do is proving everything is alright via strict clock constraints and complex inter-clock domain techniques so it can pass the STA and other test cases. However, via number theory, we can reduce the stress by proving things will work mathematically.
Quite a pleasure to be able to sit still and read through the project!